编制日期:2026年4月25日(北京时间,UTC+8)
说明:本报告基于截至2026 年4 月25 日(北京时间,UTC+8)的公开信息整理。除非特别注明,文中“编制日期”“截至时间”等内部口径均指北京时间(UTC+8);
执行摘要
- GPT-5.5 于 2026 年 4 月 23 日公开发布,OpenAI 将其定位为“用于真实工作的全新智能层级”,突出代理式编码、知识工作、计算机使用和早期科研能力。
- OpenAI 官方数据显示,GPT-5.5 在多项关键 benchmark 上优于 GPT-5.4,并在真实服务中保持与 GPT-5.4 相同的 per-token 延迟。
- 在 OpenAI API 模型目录中,gpt-5.5 已被列为复杂推理与编码旗舰模型,价格为输入 5 美元、输出 30 美元/百万 token。
- 对企业而言,GPT-5.5 的价值重点不只是“回答更聪明”,而是更能推进多步骤任务直到交付成果。
时间口径说明
1)报告内部时间:凡“编制日期”“截至时间”等,统一按北京时间(UTC+8)书写。
2)来源页面日期:若 OpenAI 官网或媒体页面仅显示“2026-04-23 / 2026-04-24”等自然日而未在页面正文显式写出时区,本文保留其原始显示日期,不自行换算。
3)若需要对外正式提交并逐条说明时区,可继续追加“原始页面日期 / 内部采用北京时间”双栏对照表。
表1 GPT-5.5 一览表
| 项目 | 内容 |
| 模型定位 | 复杂推理与编码旗舰模型;强调真实工作中的多步骤执行 |
| 公开发布日期 | OpenAI 页面显示:2026-04-23;更新说明显示:2026-04-24(原页面日期保留,未擅自换算时区) |
| 核心优势 | 代理式编码、工具使用、知识工作、早期科研、多步骤任务持续推进 |
| 官方价格 | GPT-5.5:输入 $5 / 输出 $30(每百万 token);GPT-5.4:输入 $2.5 / 输出 $15 |
| 主要可用性 | ChatGPT Plus/Pro/Business/Enterprise 与 Codex;API 亦已可用 |
| 部署提示 | 适合高难度任务;高风险场景需额外治理与人工复核 |
一、模型发布背景与定位
OpenAI Release 索引显示,GPT-5 系列在 2025 年 12 月至 2026 年 4 月间持续高频演进,从 GPT-5.2-Codex、GPT-5.3 系列、GPT-5.4 快速推进到 GPT-5.5。
在官方发布页中,GPT-5.5 被定义为“用于真实工作的全新智能层级”,核心在于理解复杂目标、调用工具、检查结果并将任务推进至完成,而非仅进行单轮问答。
从产品意义上看,GPT-5.5 代表 OpenAI 正将旗舰模型从“更会回答”进一步推进到“更会执行工作”。
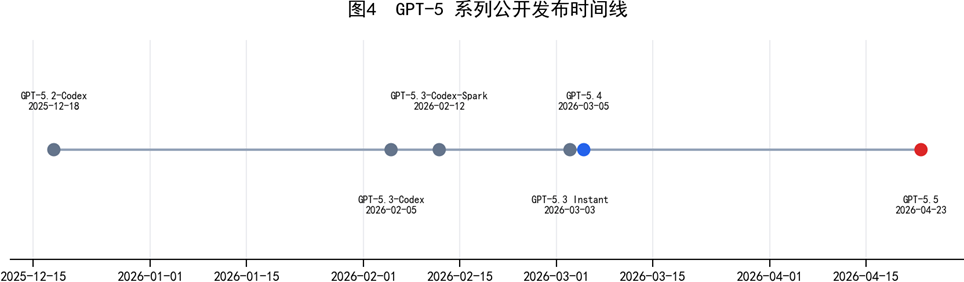
图4 GPT-5 系列公开发布时间线(图中日期保留来源公开日期)
二、能力结构:GPT-5.5 强在哪里
1)代理式编码:官方称 GPT-5.5 是其最强代理式编码模型,在 Terminal-Bench 2.0 达到 82.7%,在 SWE-Bench Pro 达到 58.6%。
2)知识工作:更适合把信息搜索、理解重点、工具调用、结果校验与输出文档/表格串成一个完整闭环。
3)计算机使用:在 OSWorld-Verified 等指标中展现了更强的软件操作与界面协同能力。
4)早期科研:更能完成证据收集、假设检验、结果解释与下一步建议。
表2 官方公开的关键基准对比
| 基准 | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| GDPval(赢/平) | 84.9% | 83.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | 78.0% | — |
| Toolathlon | 55.6% | 54.6% | — | 48.8% |
| BrowseComp | 84.4% | 82.7% | 79.3% | 85.9% |
| FrontierMath T1-3 | 51.7% | 47.6% | 43.8% | 36.9% |
| FrontierMath T4 | 35.4% | 27.1% | 22.9% | 16.7% |
| CyberGym | 81.8% | 79.0% | 73.1% | — |
| SWE-Bench Pro(公开) | 58.6% | 57.7% | — | — |
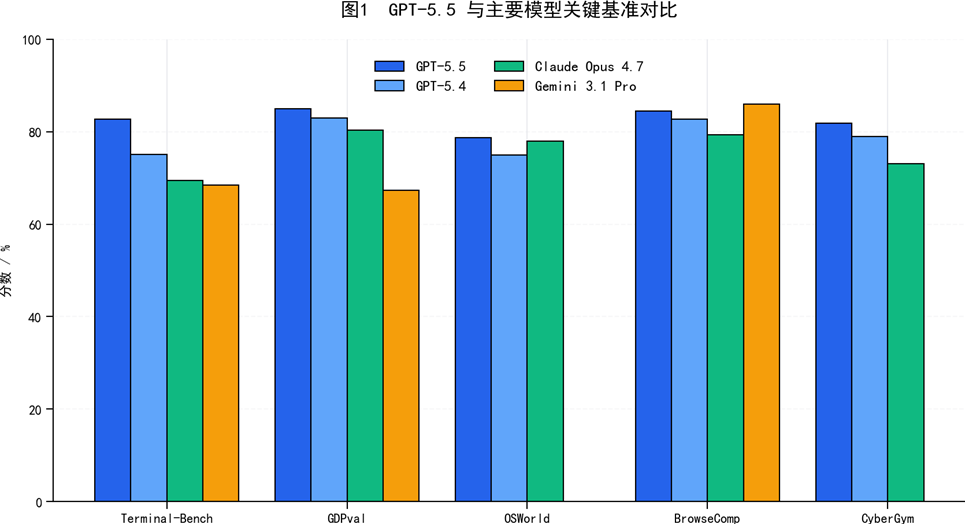
图1 GPT-5.5 与主要模型关键基准对比
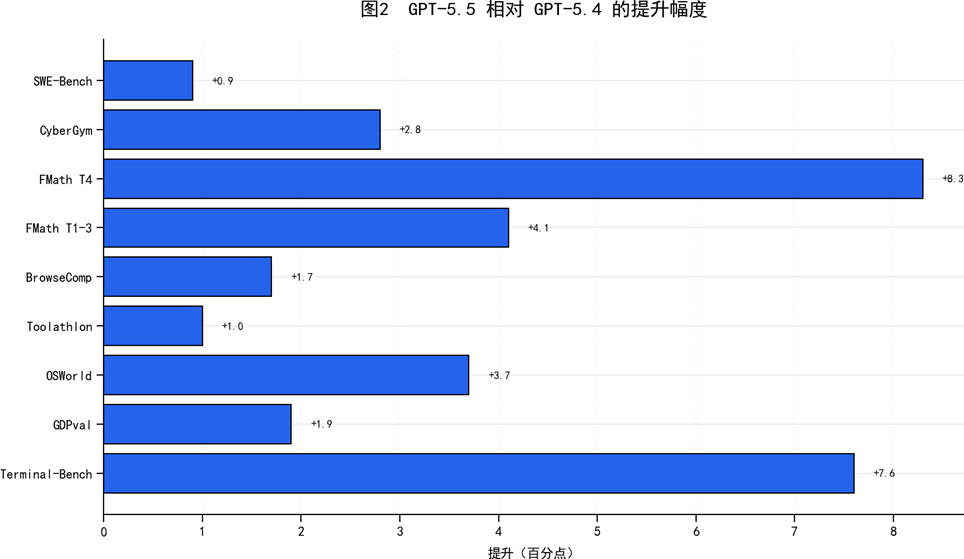
图2 GPT-5.5 相对 GPT-5.4 的提升幅度
三、价格、可用性与选型建议
API 模型目录显示,gpt-5.5 已成为复杂推理与编码旗舰模型,其价格高于 GPT-5.4:输入价格从 2.5 美元上升至 5 美元,输出价格从 15 美元上升至 30 美元。
评估 GPT-5.5 的价值时,不应只看单 token 成本,更应结合任务完成率、重试次数、人工监督成本与总交付时长。
建议将 GPT-5.5 作为高难度任务默认首选,将 GPT-5.4 或 mini 系列保留给成本敏感型或高吞吐型任务。
表3 官方价格与适配场景对比
| 模型 | 输入价格($/MTok) | 输出价格($/MTok) | 适配场景 |
| GPT-5.5 | 5.0 | 30.0 | 复杂推理与编码旗舰 |
| GPT-5.4 | 2.5 | 15.0 | 更具性价比的专业工作模型 |
| GPT-5.4 mini | 0.75 | 4.5 | 低延迟/低成本工作负载 |
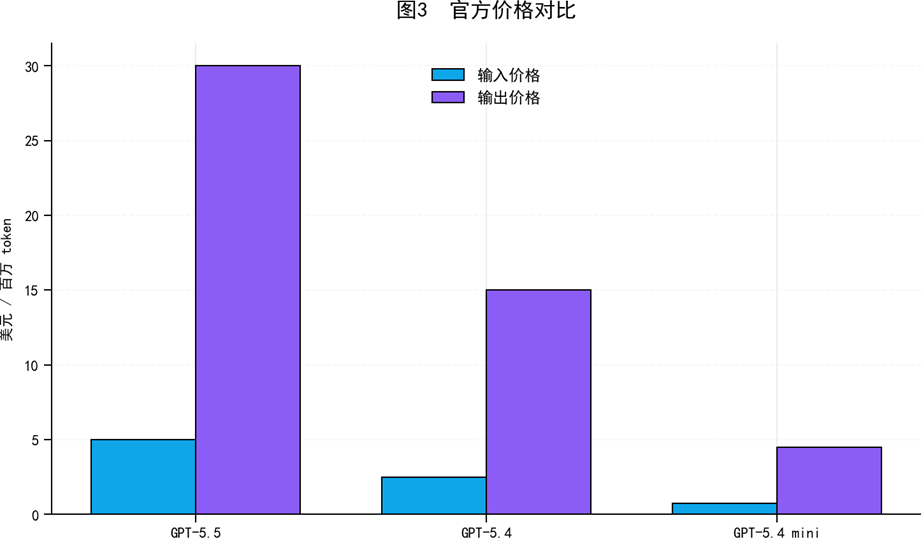
图3 官方价格对比
四、企业落地建议
研发团队应优先在高上下文、高耦合代码库的长链路任务中试点,如重构、缺陷定位、测试补齐与回归验证。
业务团队适合从“材料多、步骤多、可验证”的流程切入,例如投研摘要、销售报告、财务核对和知识库整编。
建议建立三项核心指标:端到端完成率、人工返工率、单位成果总成本。
表4 企业典型场景与建议 KPI
| 场景 | 推荐模型 | 可交付成果 | 建议 KPI |
| 大型代码库维护/重构 | GPT-5.5 | 补丁、测试、重构说明、回归验证 | 首次通过率、缺陷回归率、总耗时 |
| 投研/行业研究 | GPT-5.5 | 研究摘要、对比表、风险清单、PPT 草稿 | 引用准确率、分析深度、审核通过率 |
| 财务/运营报表 | GPT-5.5 或 GPT-5.4 | 表格清洗、异常标注、周/月报 | 处理时长、人工复核比例、错误率 |
| 高吞吐分类/简单客服 | GPT-5.4 mini | 标签、回复草稿、工单路由 | 吞吐量、平均成本、准确率 |
五、风险与治理
OpenAI 官方称 GPT-5.5 采用了迄今最强的一组 safeguards,包括红队测试、针对高级网络安全与生物能力的专项评估,以及早期伙伴的真实场景反馈。
媒体交叉验证指出,GPT-5.5 未越过“Critical”网络安全风险阈值,但达到“High”级别,因此实际部署需引入更严格的权限管理、日志审计和人工复核。
在高风险行业中,更推荐“人机协同增效”而不是完全自动替代。
六、结论
GPT-5.5 不只是 GPT-5.4 的常规增强,更像是一次“工作完成度”的提升:更强的目标理解、更主动的工具调用、更持续的多步骤推进。
对组织来说,它的真正意义在于把 AI 从“内容生成器”推进到“工作执行器”。
建议优先在高价值、长流程、强验证场景中落地 GPT-5.5,在高吞吐、低复杂度场景中继续使用 GPT-5.4 或 mini,以获得更优总体成本结构。
附录:参考资料
时区口径补充:本报告不将源站未明确标注时区的发布日期擅自换算为某一时区;仅对“报告编制日期/截至时间”明确采用北京时间(UTC+8)。如需正式对外提交版本,可继续追加“源站显示日期(原文)/内部采用口径(北京时间)”对照表。
[1] OpenAI. Introducing GPT-5.5. 2026-04-23 / 2026-04-24 update.
[2] OpenAI API. Models. gpt-5.5 官方模型目录与价格。
[3] OpenAI Research | Release. GPT-5 系列发布索引。
[4] OpenAI API. GPT-5.4 Model. 用于价格和定位对比。
[5] CNBC. OpenAI announces GPT-5.5, its latest artificial intelligence model. 用于交叉验证。
发表回复